
读 ncnn 源码(Ⅴ):Param 读取闭环——从 token 到图,再到 I/O 名单
读 ncnn 源码(Ⅴ):Param 读取闭环——从 token 到图,再到 I/O 名单
这一篇把 “ncnn 如何读取 .param 并把它变成一张可执行的计算图” 的最后一段细节补齐:
① ParamDict 的数据布局 / 类型系统 / 读写语义;
② 迷你词法器 vstr_* 如何把字符串切成标量/数组;
③ Blob 的生产者/消费者是怎样被填充;
④ update_input_output_indexes/names 如何自动识别模型输入输出。
我们再用一段简化的 SqueezeNet 片段做“逐 token 实录”。
TL;DR
ParamDict 内部是一块 定长槽位数组(NCNN_MAX_PARAM_COUNT):每个 id 对应一个 type + (i/f/v/s),类型码包括标量/数组/字符串。
load_param() 扫描 id=value / id=v1,v2,...,用 vstr_is_string/float 断型,vstr_to_float 手写解析。
建图时,每个 layer 读完头(type/name/bottom/top)和 Par ...

读 ncnn 源码(Ⅳ):Convolution 基类与 x86/FMA 特化 —— 参数到算子的全链路
读 ncnn 源码(Ⅳ):Convolution 基类与 x86/FMA 特化 —— 参数到算子的全链路
这一篇把镜头对准 ncnn 最常用的算子之一 Convolution。我们先看 基类 Convolution 如何从 ParamDict 接住参数、管理权重与激活,再看 x86/FMA 特化层 Convolution_x86_fma 如何在运行时“接管”并进行更激进的优化(packing、Winograd/sgemm 预变换等)。最后用真实 .param 片段把字段一一落位。
TL;DR
Convolution::load_param(pd) 明确了 参数键位表。
dynamic_weight=1 会把 one_blob_only=false,意味着第二个 bottom 用来动态传入权重(运行时卷积),否则权重来自 load_model()。
int8_scale_term=1 需要编译 NCNN_INT8,并设置 support_int8_storage=true。
padding 支持特殊值 -233=SAME_UPPER、-234=SAME_LOWER;make_p ...

读 ncnn 源码(Ⅲ):ParamDict 解析、featmask 按层屏蔽、词法器与 blob 索引(含解析实录)
读 ncnn 源码(Ⅲ):ParamDict 解析、featmask 按层屏蔽、词法器与 blob 索引(含解析实录)
承接前两篇:我们已经理清了 Net::load_param 的主链路与层工厂/覆盖/CPU 指令集优选。本篇把镜头拉近到每一层行尾那串 k=v 参数,以及与之相关的三个关键点:
① ParamDict::load_param 的语法与类型系统;
② featmask 如何把全局 Option 变成按层屏蔽的局部选项;
③ find_blob_index_by_name / vstr_* 这些“小工具”在建图与解析中的位置。最后用一段真实 .param(SqueezeNet 的前两层)做逐 token 解析实录。
TL;DR
ParamDict::load_param(dr) 循环读取 id=value / id=v1,v2,...,支持 int / float / string / int[] / float[] 五种类型;同时兼容“旧式数组语法”(负 id 前缀 + 显式长度)。
解析结果落在 d->params[id],type 编码:2=int、 ...

读 ncnn 源码(Ⅱ):层工厂与“覆盖机制”,以及 CPU 端的指令集优选
读 ncnn 源码(Ⅱ):层工厂与“覆盖机制”,以及 CPU 端的指令集优选
延续前文对 Net::load_param 的解析,这一篇聚焦两件事:
① ncnn 如何把 字符串层名 映射到 内置层 并允许你覆盖默认实现;
② CPU 端如何在运行时按 AVX512/FMA/AVX/… 等指令集优选最快实现,并且逐层回退兜底。
TL;DR
layer_registry[] 是内置层名册:把 "Convolution" 这类字符串类型映射到typeindex,并关联一个 creator(工厂函数指针)。
create_overwrite_builtin_layer(...) 让你按 typeindex 覆盖内置实现(优先级最高,早于 Vulkan/CPU 路径)。
create_layer_cpu(...) 会在运行时检测 CPU 能力,从高到低选择 AVX512 → FMA → AVX → LASX → LSX → MSA → XTheadVector → RVV → arch 基线;若该 ISA 下此层没特化实现,自动回退到更通用实现。
Net::load_param 的创 ...

读 ncnn 源码(Ⅰ):从 sample 到 `Net::load_param` 的完整链路
读 ncnn 源码(Ⅰ):从 sample 到 Net::load_param 的完整链路
目标:弄清 ncnn 是如何从 .param / .bin 文件构建计算图、如何适配不同输入来源(文件/内存)、以及在 Vulkan 设备存在时如何裁剪与回退。
TL;DR
squeezenet 样例的主流程:load_param(解析网络结构与超参数)→ load_model(载入权重)→ create_extractor / input / extract(执行推理)。
I/O 入口通过 DataReader 抽象统一,DataReaderFromStdio(FILE*) 只是其中一种实现。文本解析走 scan(),二进制走 read()/reference()。
Net::load_param(DataReader&) 是文本 .param 的总入口:读魔数与计数 → 逐层解析(类型、名字、bottom/top、ParamDict)→ 处理 shape hint(键30) 与 featmask(键31) → 按需 Vulkan→CPU 回退 → 更新网络输入输出。
错误策 ...
AI infra 合集
TensorRT
从 0 到 1:TensorRT-OSS 编译与上手(含 Windows 与 Linux)
ncnn
ncnn 是一个为手机端极致优化的高性能神经网络前向计算框架。 ncnn 从设计之初深刻考虑手机端的部署和使用。 无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架。 基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行, 开发出人工智能 APP,将 AI 带到你的指尖。 ncnn 目前已在腾讯多款应用中使用,如:QQ,Qzone,微信,天天 P 图等。Github
读 ncnn 源码笔记:从 sample 到 Net::load_param 的完整链路
读 ncnn 源码(Ⅱ):层工厂与“覆盖机制”,以及 CPU 端的指令集优选
读 ncnn 源码(Ⅲ):ParamDict 解析、featmask 按层屏蔽、词法器与 blob 索引(含解析实录)
读 ncnn 源码(Ⅳ):Convolution 基类与 x86/FMA 特化 —— 参数到算子的全链路
读 ncnn 源码(Ⅴ):Param 读取闭环——从 token 到图,再 ...

从 0 到 1:TensorRT-OSS 编译与上手(含 Windows 与 Linux)
从 0 到 1:TensorRT-OSS 编译与上手(含 Windows 与 Linux)
这篇文章记录了我在本地从源码编译 TensorRT-OSS 的完整流程,目标读者是准备二次开发插件、研究解析器(ONNX Parser)或想阅读示例代码的人。
背景简介
TensorRT-OSS 仓库包含 TensorRT 的开源组件:插件源代码、ONNX 解析器以及大量示例(samples)。这些组件是 TensorRT GA(商用发行包)的子集与扩展,便于我们调试与学习。
一、准备工作(Prerequisites)
1) 必备软件(核心)
TensorRT GA 发行包(与 OSS 匹配的版本,例如:v10.13.3.9)
CUDA(推荐:12.9 / 13.0)
cuDNN(可选) 8.9
CMake ≥ 3.31
Python 3.10–3.13、pip ≥ 19.0
基本工具:git、pkg-config、wget(Linux);Windows 需 VS 2022 + 组件(含 C++、CUDA)
备注:onnx-tensorrt、cub、protobuf 会由 T ...
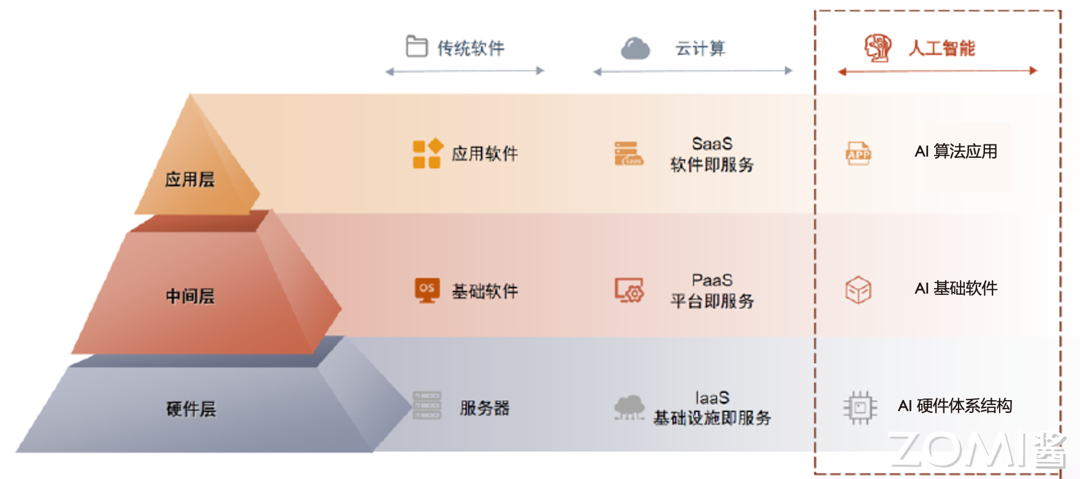
AI System - 介绍
AISystem是由ZOMI的开源课程,本文是我在学习过程中的笔记。
AI 的历史与现状
AI 的领域应用
人工智能正在日益渗透到所有的技术领域,而深度学习是目前人工智能中最活跃的分支。
CV 领域应用
“计算机视觉,尤其是图像识别,是深度学习能力的一些最早重要演示的主题。”
“自动驾驶汽车使用深度学习来识别和跟踪…车辆、行人和其他物体。”
“搜索引擎…根据图像查询提供准确且相关的搜索结果。”
“机场和政府大楼使用面部识别来筛查乘客和员工。”
“已从…图片分类、目标检测和物体分割,逐渐过渡到…二维甚至三维的图片生成。”
NLP 领域应用
“深度学习与 NLP 有着密切的联系…研究如何让计算机更好地理解和处理自然语言。”
“词向量表示…更好地捕捉词语的语义信息。”
“使用 CNN/RNN 等模型,对文本进行分类或情感分析。”
“机器翻译…利用大量双语语料库进行训练,从而实现高质量的机器翻译。”
“最新的进展已经能够使用语言大模型 LLM 实现人机对话、摘要自动生成和信息检索等功能。”
Audio 领域应用
“智能音频处理…实现音频信号的分析、识别和合成等任 ...

在 Ubuntu 上编写通用脚本管理 Clash 全局代理
在 Ubuntu 上编写通用脚本管理 Clash 全局代理
在 Linux 下使用 Clash 代理时,我们通常需要手动启动 Clash 程序,并设置 http_proxy、https_proxy 等环境变量来实现全局代理。如果频繁切换代理,这样做会非常麻烦。
本文将演示如何编写一个通用脚本,一键启动或关闭 Clash,并实现全局代理切换。
1. Clash 启动命令回顾
假设 Clash 的配置文件路径为:
1~/.config/clash/config.yaml
手动启动方式为:
1clash -f ~/.config/clash/config.yaml
默认 REST API 监听在 9090 端口,代理监听在 7890 端口。
2. 编写代理控制脚本
新建一个脚本文件 proxy.sh:
1nano proxy.sh
写入以下内容:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960#!/bin/b ...

openEuler WiFi 无法访问公网的排查与解决笔记
openEuler WiFi 无法访问公网的排查与解决笔记
在使用 openEuler 系统连接 WiFi 时,我遇到了 WiFi 已连接但无法访问公网 的问题。本文记录了从问题发现到解决的完整排查过程,方便未来遇到类似情况参考。
一、问题现象
在 openEuler 上使用 nmcli 查看网络状态:
1nmcli device status
输出显示:
123wlan0 wifi connected CAD330BS1usb0 ethernet connected usb0-static...
可以看到无线网卡 wlan0 已经成功连接到 WiFi(SSID:CAD330BS1),但是尝试 ping 公网:
12ping www.baidu.comping 114.114.114.114
结果均提示:
12ping: socket: Operation not permittedping: Destination Host Unreachable
二、初步诊断
普通用户权限问题
ping 报错 “Ope ...

PyTorch FractionalMaxPool3d解析
PyTorch FractionalMaxPool3d解析
函数入口
主要负责核心处理逻辑前的数据检查以及运行时类型。运行时类型靠AT_DISPATCH_FLOATING_TYPES_AND2宏实现,可展开查看。lambda表达式负责实际的逻辑执行。
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768TORCH_IMPL_FUNC(fractional_max_pool3d_out_cpu)( // 核心输入张量。这是需要进行分数最大池化操作的特征图。 // 它的形状通常是 4D [C, T, H, W](通道, 时间, 高度, 宽度)或 5D [N, C, T, H, W](批次, 通道, 时间, 高度, 宽度)。 // 函数内部会首先将其转换为内存连续的 (contiguous) 版本以提高计算效率。 对应算子参数input. const at::Tensor& ...

有限元方法刚度矩阵K详细表达式推导
三维刚度矩阵K的详细推导
前置弹性力学矩阵知识
几何变换矩阵S
S=[∂∂x000∂∂y000∂∂z∂∂y∂∂x00∂∂z∂∂y∂∂z0∂∂x](1.1)\mathbf{S} =
\begin{bmatrix}
\frac{\partial}{\partial x} & 0 & 0 \\
0 & \frac{\partial}{\partial y} & 0 \\
0 & 0 & \frac{\partial}{\partial z} \\
\frac{\partial}{\partial y} & \frac{\partial}{\partial x} & 0 \\
0 & \frac{\partial}{\partial z} & \frac{\partial}{\partial y} \\
\frac{\partial}{\partial z} & 0 & \frac{\partial}{\partial x}
\end{bmatrix}\tag{1.1}
S=⎣⎢⎢⎢⎢⎢⎢⎢⎡ ...

有限元方法大纲-弹性力学
有限元方法思维导图
刚度矩阵详细推导
请看另一篇文章
该封面图片由Thiago de Paula Oliveira在Pixabay上发布

Linux系统硬盘爆了?可能是因为Docker日志文件
Linux系统硬盘爆了?可能是因为Docker日志文件
定位问题
1df -h
1234567891011121314文件系统 大小 已用 可用 已用% 挂载点overlay 3.5T 3.4T 0 100% /var/lib/docker/overlay2/e45ac69ad614de49cc50e66d404e159e86532193608da7315ca33aa776e426ab/mergedoverlay 3.5T 3.4T 0 100% /var/lib/docker/overlay2/3943e7de3bee9fa4d6df1e2dfc41d6270d11d99e79869246763033361e47e2cb/mergedoverlay 3.5T 3.4T 0 100% /var/lib/docker/overlay2/2854576b609fd3e9ea2f2ce422fdc072dc336e7 ...

LMDeploy+Open Web UI部署DeepSeek
LMDeploy部署deepseek
Miniconda安装
1234mkdir -p ~/miniconda3wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.shbash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3rm -rf ~/miniconda3/miniconda.sh
1~/miniconda3/bin/conda init bash
1source ~/.bashrc
LMDeploy下载
123conda create -n lmdeploy python=3.8 -yconda activate lmdeploypip install lmdeploy
模型准备
1.下模地址
huggingface
https://huggingface.io
魔塔社区
https://www.modelscope.cn
找到模型后赋值其名称ID即可。
2. 模 ...

Ollama+Open Web UI部署DeepSeek
前言
本文使用Docker、Ollama以及Open WebUI在Linux部署本地模型,实现web式访问大模型。
工具安装
Ollama
运行命令
1curl -fsSL https://ollama.com/install.sh | sh
Docker
1. 安装 Docker
步骤 1.1: 更新系统
在安装 Docker 之前,确保系统是最新的:
12sudo apt update sudo apt upgrade -y
步骤 1.2: 安装必要的依赖
安装一些必要的依赖包:
1sudo apt install -y apt-transport-https ca-certificates curl software-properties-common
步骤 1.3: 添加 Docker 官方 GPG 密钥
1curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.g ...



